We are currently witnessing a massive schism in the AI community. There are now two distinct worlds of AI enthusiasts, and they are drifting further apart every day.
World 1: The Optimists (The Boardroom) This group sees a future that is just around the corner. They look at the benchmarks, the impressive demos, and the exponential curves. They are baffled as to why deployment is taking so long.
World 2: The Confused Practitioners (The Engine Room) This group is scratching their heads. They are asking, "Why does this thing break the moment we step outside the sandbox?" They are seeing the hallucinations, the lack of reliability, and the integration nightmares.
Why the massive disconnect?

To understand this, we have to look back at the last time we promised a technological utopia.
The Waymo Lesson: Physics vs. Metaphor
15 years ago, Google started "Project Chauffeur" (which became Waymo). The excitement was electric. VC money poured in, and experts predicted Level 5 autonomy in a few short years. The narrative was that cars were becoming "computers on wheels."
But then the industry collapsed into reality - and few have survived until today. Why? Because the physics never changed. Only the metaphor did. Driving isn't just a data problem; it's an entropy problem. The real world is chaotic, unpredictable, and infinitely messy. We solved the "99% highway" problem easily, but the "1% city chaos" problem remains brutally hard.

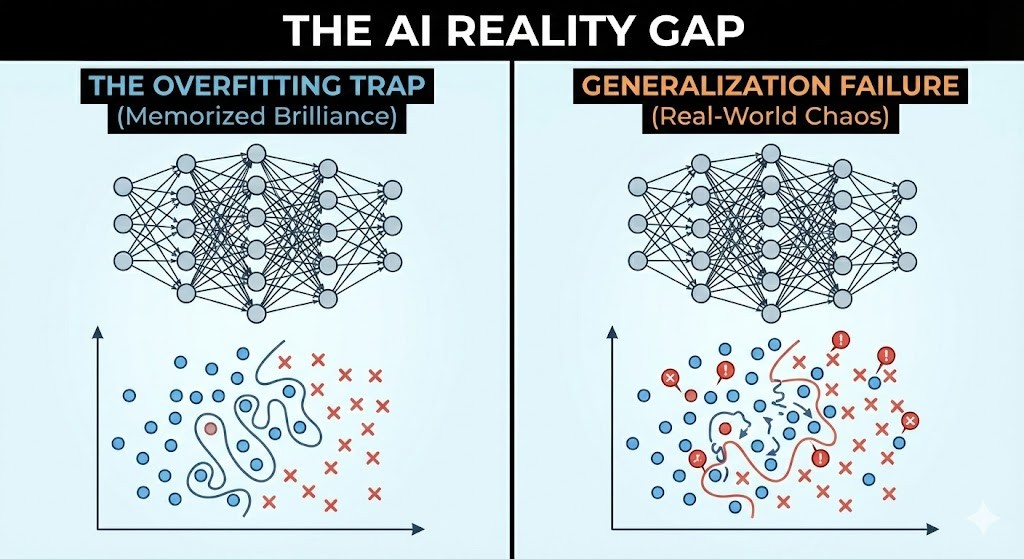
The "Overfitting" Trap
Today, we are seeing the exact same pattern with LLMs and Generative AI. The fundamental reason for the gap between promise and reality is uncomfortable but simple:
Today's AI is, fundamentally, an advanced overfitting mechanism. (remember - overfitting is always the starting point for any new model training)
- The Optimists evaluate models on tasks that resemble the training data—the "curated," "memorized," and "clean" examples. In this domain, the model looks like a genius.
- The Practitioners force the model to handle the messy reality of their specific business data, which was not in the training set. It is noisy, unstructured, and full of edge cases.
The model isn't "reasoning" through this new messiness; it is trying to map it to a memorized pattern that doesn't exist. Just like self-driving cars, the "demo" is easy because the demo is controlled. The "product" is hard because the real world is not curated.
We need to stop evaluating AI on how well it answers standardized test questions and start evaluating it on how well it handles the chaotic, boring, uncurated data of the real enterprise.