
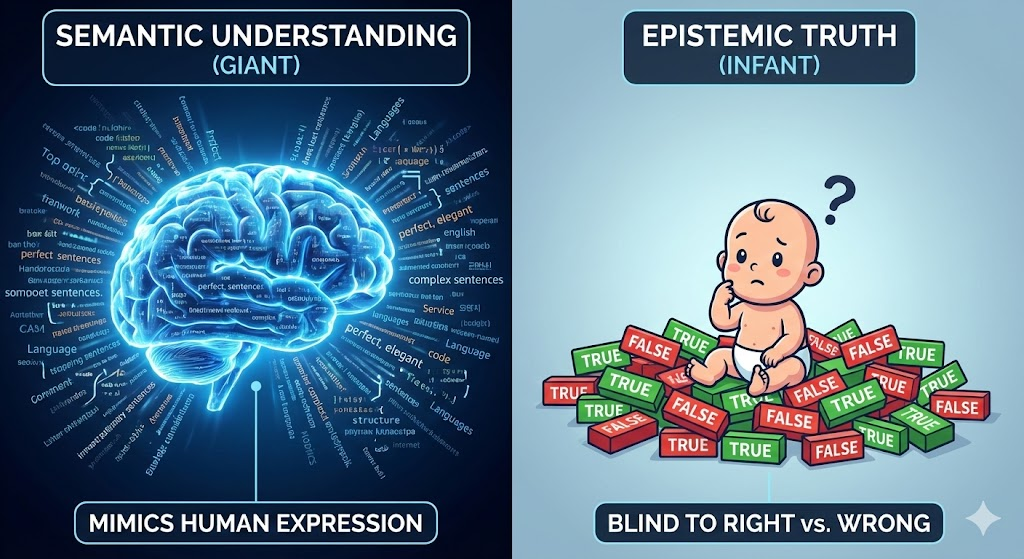
We need to have an honest engineering conversation about what a Large Language Model actually is, versus what we want it to be. If you strip away the hype, today’s LLMs are fundamentally Semantic Engines. By digesting the entire public web, they have become perfect mimics of human expression. They understand syntax, tone, and the statistical relationship between words better than most humans. They can rewrite a Python script in the style of Shakespeare because they have mapped the semantic probability of those tokens.
But here is the design flaw we are ignoring: Semantic understanding is not Truth.
The Plausibility Feature (and Bug)
LLMs are probabilistic, next-token predictors. They are not designed to verify facts; they are designed to maximize plausibility.
- The Strength: This makes them incredible creative partners and translators.
- The Weakness: They cannot inherently distinguish right from wrong amongst noise. If the training data contains 1,000 conflicting opinions, the model doesn't find the truth; it averages the noise. In the enterprise, this is fatal.
Enterprise data is full of noise—outdated specs, conflicting wikis, and deprecated code. The model, lacking any concept of ground truth, treats a document from 2018 with the same semantic weight as one from 2024. It doesn't know what is right; it only knows what looks likely.
The Missing "Dark Matter" (Unwritten Knowledge)

The biggest limitation of models isn't what they read; it's what they can't see. Models train on artifacts (documents, code, emails). But true intelligence relies on the process—the unwritten heuristics, the hallway conversations, and the "tribal knowledge" that explains why a decision was made.
This is the "Dark Matter" of the enterprise. It is untrainable because it was never written down. When an LLM tries to reason without this map, it is Hallucinating by default—filling in the gaps of your uncaptured process with statistical guesses.
The "Large Context" Fallacy
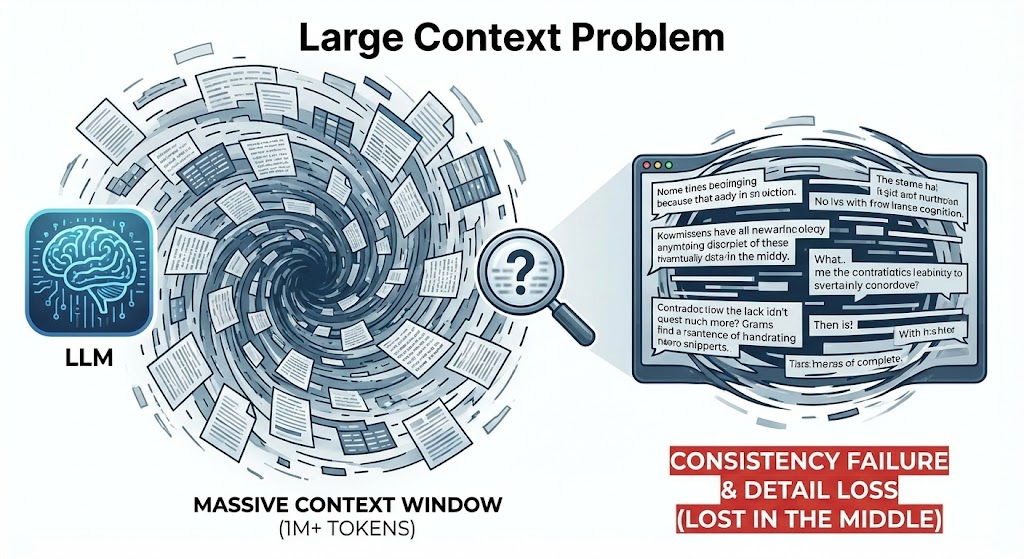
We are trying to patch this with massive context windows (1M+ tokens). But models are notoriously bad at digesting large, unstructured blobs.
- The Consistency Problem: Across a 500-page PDF, a model struggles to maintain a consistent worldview. It contradicts itself.
- The Detail Loss: "Lost in the Middle" is real. Models gloss over critical, needle-in-the-haystack details that define mission-critical workflows.
The Agentic Reality
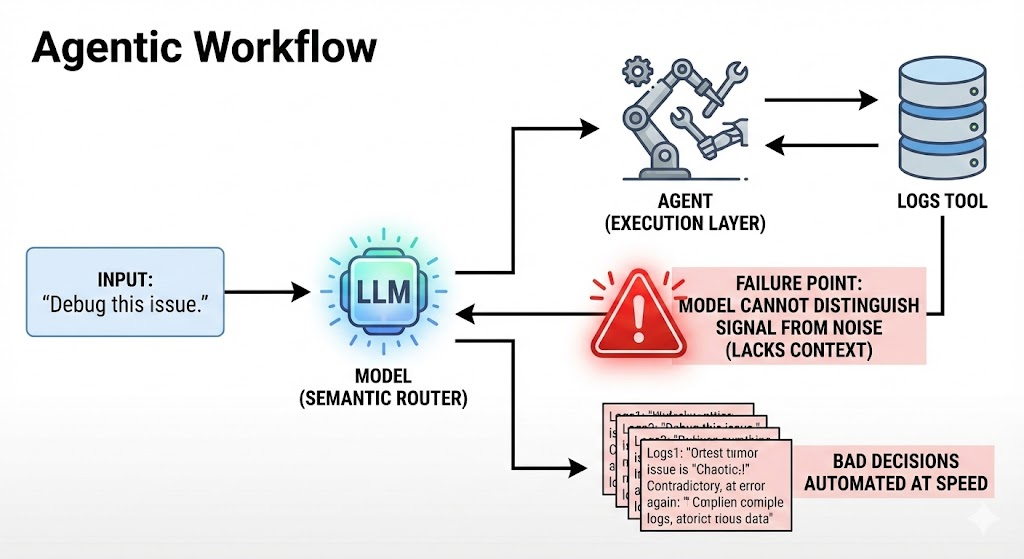
This brings us to Agents. Agents are a brilliant architectural pattern. They leverage the Model’s semantic power to navigate complex problems, using the Model as a "Router" to call tools (APIs, SQL, Browsers) at runtime.
The workflow is logical:
- Input: "Debug this issue."
- Model: Understands the intent (Semantic).
- Agent: Calls the 'Logs' tool (Execution).
- Model: Interprets the log (Semantic).
But here is the catch: An Agent is only as good as the context it can retrieve. If the underlying model cannot distinguish the "Right Log" from the "Noise," or if it lacks the "Tribal Knowledge" to know where to look, the Agent just automates bad decisions at machine speed.
The Conclusion
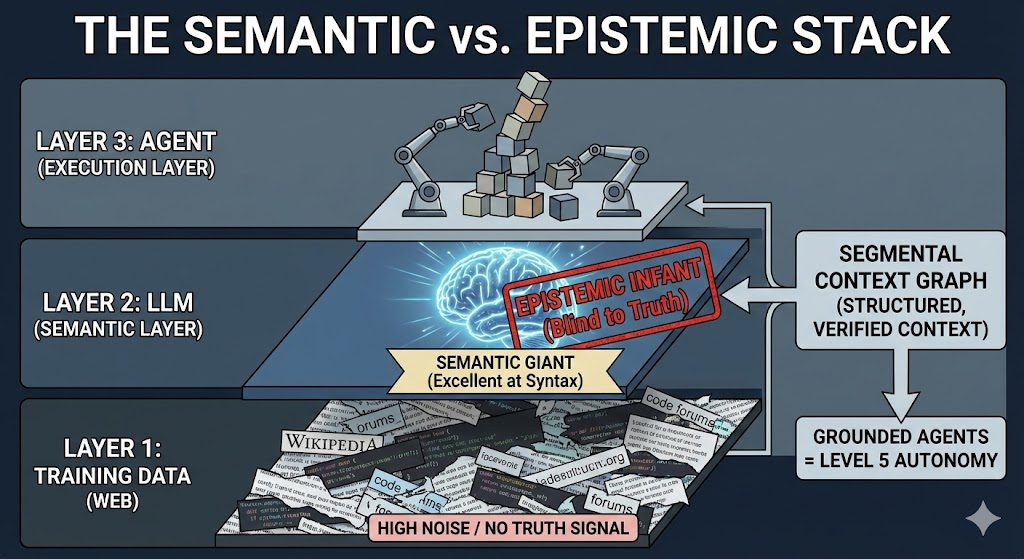
We are trying to build Level 5 autonomy on top of Level 1 context. The bottleneck isn't the Model's reasoning capability. It is our failure to provide the Structured, Verified Context required to point that reasoning in the right direction.
Agents don't need to be smarter. They need to be grounded.