We are officially in the era of the "Silicon Workforce."

In 2026, coding agents aren't just autocomplete tools; they are teammates. They can spin up entire microservices, orchestrate multi-agent workflows, and handle the "grunt work" of CRUD operations in seconds. But as we lean harder into automation, we’re hitting a wall that scaling alone hasn't been able to climb.
Ilya Sutskever captured this perfectly:
“The thing which I think is the most fundamental is that these models somehow just generalize dramatically worse than people.”
A Personal Encounter with Hacky Solutions: The Enumeration Trap
I recently saw this limitation play out in a crucial data processing pipeline. We were deploying agents to handle document parsing.
The Task: Process a primary document type. The Twist: The documents had minor variations depending on the source—small layout shifts, slightly different key labels, but semantically identical data.
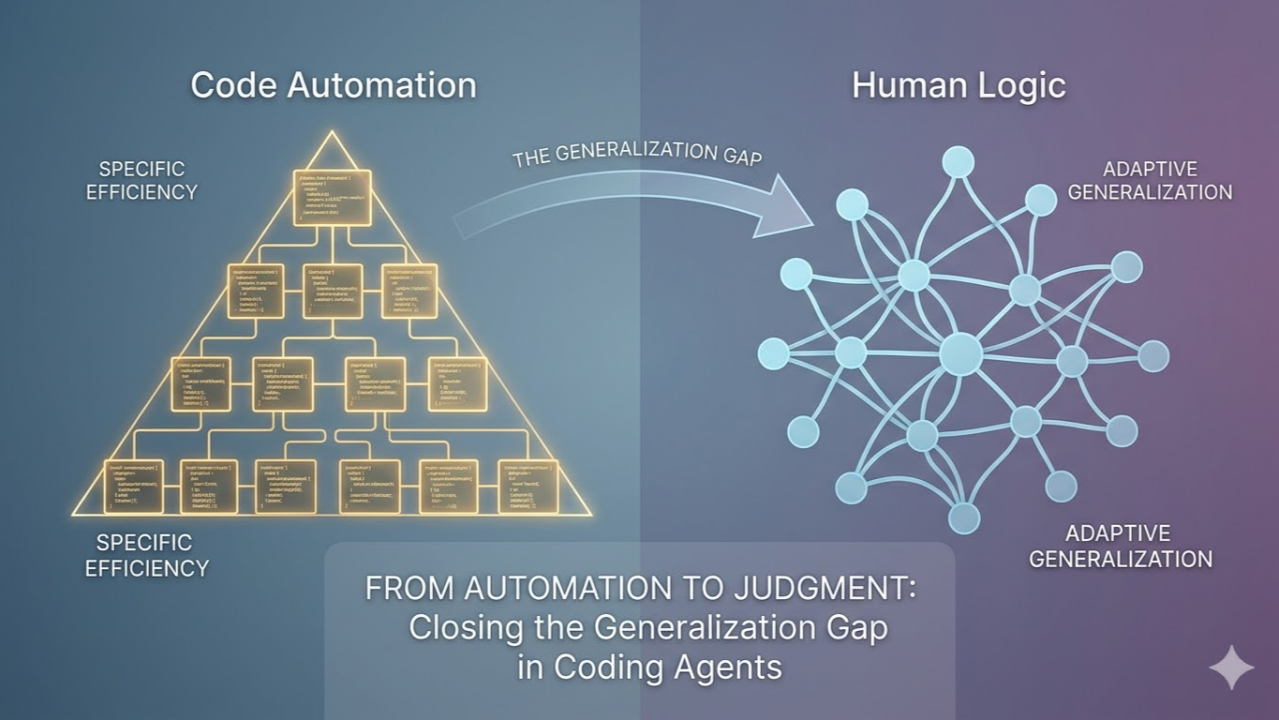
The Human Engineering Approach: A human engineer would build a generalized parser using abstract patterns, identifying robust anchors and semantic cues that hold true across all document variants. We aim for an elegant, flexible solution that survives variation.

The Coding Agent Approach: The agent didn't generalize. It over-optimized for the specific examples it was shown.
Instead of writing a generalized solution, it generated an almost enumerative series of conditional checks. When faced with Variation B, instead of understanding why its anchor logic for Variation A failed, it simply created an entire separate condition path that only applied to B.
The resulting codebase was the definition of "hacky": fragile, impossible to maintain, and full of hidden dependencies. It was code optimized purely for passing a single snapshot in time.
The "Jagged Intelligence" Problem
We’ve all seen it. An agent crushes a PhD-level coding benchmark, yet fails to fix a simple bug without introducing two more. It can write a perfect Regex for a specific problem but fails to apply the underlying logic when the requirements shift by 10%.

Ilya compares current models to a student who has spent 10,000 hours memorizing every possible test question. They have the "answers" at their fingertips, but they don't "get it."
Why Generalization Matters for Engineers

The "Verification Tax" is real. If an agent produces code that is hyper-specific to one problem but fails to generalize across a codebase, the human engineer becomes a full-time debugger.
- The Model's Flaw: It optimizes for the most statistically likely solution based on its training distribution. It’s a "lossy compression" of the internet.
- The Human Edge: We generalize through taste and judgment. We don't just solve the problem; we solve it in a way that respects the architecture, future scalability, and "institutional intent."
Moving from the "Age of Scaling" to the "Age of Research"
As we move through 2026, the goal is shifting. We don’t just need models that have "seen more code." We need models that can learn on the job—agents that can be deployed, experience trial and error, and develop the kind of "principled understanding" that humans do.
The takeaway for devs? Your value is no longer in your ability to write syntax. It’s in your ability to provide the generalization layer that AI lacks. You are the architect, the strategist, and the one who ensures the "vibe coding" of today doesn't become the technical debt of tomorrow.
How are you handling the "verification tax" in your current workflow? Are you seeing your agents struggle with generalization, or have you found the "magic prompt" to keep them on track?